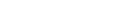
The multi-cue boundary detection dataset
Video collection
In order to study the interaction of several early visual cues (luminance, color, stereo, motion) during boundary detection in challenging natural scenes, we have built a multi-cue video dataset composed of short binocular video sequences of natural scenes using a consumer-grade Fujifilm stereo camera (Mély, Kim, McGill, Guo and Serre, 2016). We considered a variety of places (from university campuses to street scenes and parks) and seasons to minimize possible biases. We attempted to capture more challenging scenes for boundary detection by framing a few dominant objects in each shot under a variety of appearances. Representative sample keyframes are shown on the figure below. The dataset contains 100 scenes, each consisting of a left and right view short (10-frame) color sequence. Each sequence was sampled at a rate of 30 frames per second. Each frame has a resolution of 1280 by 720 pixels.

A few representative frames from our dataset, along with the boundary annotations averaged across subjects. Darker lines means higher human agreement. Note that the annotated contours have been dilated for display purposes.
Ground truth annotations
We collected two sets of hand-annotations for the last video frame of the left image for every scene: one for object boundaries, and one for “lower-level” edges. Hand-segmentation was performed by paid undergraduate students at Brown University (Providence, RI). We wrote custom custom Java software to enable manual annotations within a web browser. Annotators were not limited in the amount of time they had available to complete the task. The segmentation involved annotating contours that defined the boundary of each object’s visible surface regions. We gave all annotators the same basic instructions as done in Martin, Fowlkes, and Malik (2004): “You will be presented a photographic image. Divide the image into some number of segments, where the segments represent things or parts of things in the scene. The number of segments is up to you, as it depends on the image. Something between 2 and 30 is likely to be appropriate. It is important that all of the segments have approximately equal importance.”
The dataset can be downloaded here (around 3.4 GB in size).
- Databases
- ClickMe
- The multi-cue boundary detection dataset
- HMDB: a large human motion database
- The Breakfast Actions Dataset