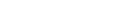
The Breakfast Actions Dataset

Introduction
Illustration of the Actions
Citation
Download
Current Benchmarks
About the page
Introduction
A common problem in computer vision is the applicability of the algorithms developed on the meticulously controlled datasets on real world problems, such as unscripted, uncontrolled videos with natural lighting, view points and environments. With the advancements in the feature descriptors and generative methods in action recognition, a need for comprehensive datasets that reflect the variability of real world recognition scenarios has emerged.
This dataset comprises of 10 actions related to breakfast preparation, performed by 52 different individuals in 18 different kitchens. The dataset is to-date one of the largest fully annotated datasets available. One of the main motivations for the proposed recording setup “in the wild” as opposed to a single controlled lab environment is for the dataset to more closely reflect real-world conditions as it pertains to the monitoring and analysis of daily activities.
The number of cameras used varied from location to location (n = 3 − 5). The cameras were uncalibrated and the position of the cameras changes based on the location. Overall we recorded ∼77 hours of video (> 4 million frames). The cameras used were webcams, standard industry cameras (Prosilica GE680C) as well as a stereo camera (BumbleBee , Pointgrey, Inc). To balance out viewpoints, we also mirrored videos recorded from laterally-positioned cameras. To reduce the overall amount of data, all videos were down-sampled to a resolution of 320×240 pixels with a frame rate of 15 fps.
Cooking activities included the preparation of:
- coffee (n=200)
- orange juice (n=187)
- chocolate milk (n=224)
- tea (n=223)
- bowl of cereals (n=214)
- fried eggs (n=198)
- pancakes (n=173)
- fruit salad (n=185)
- sandwich (n=197)
- scrambled eggs (n=188).
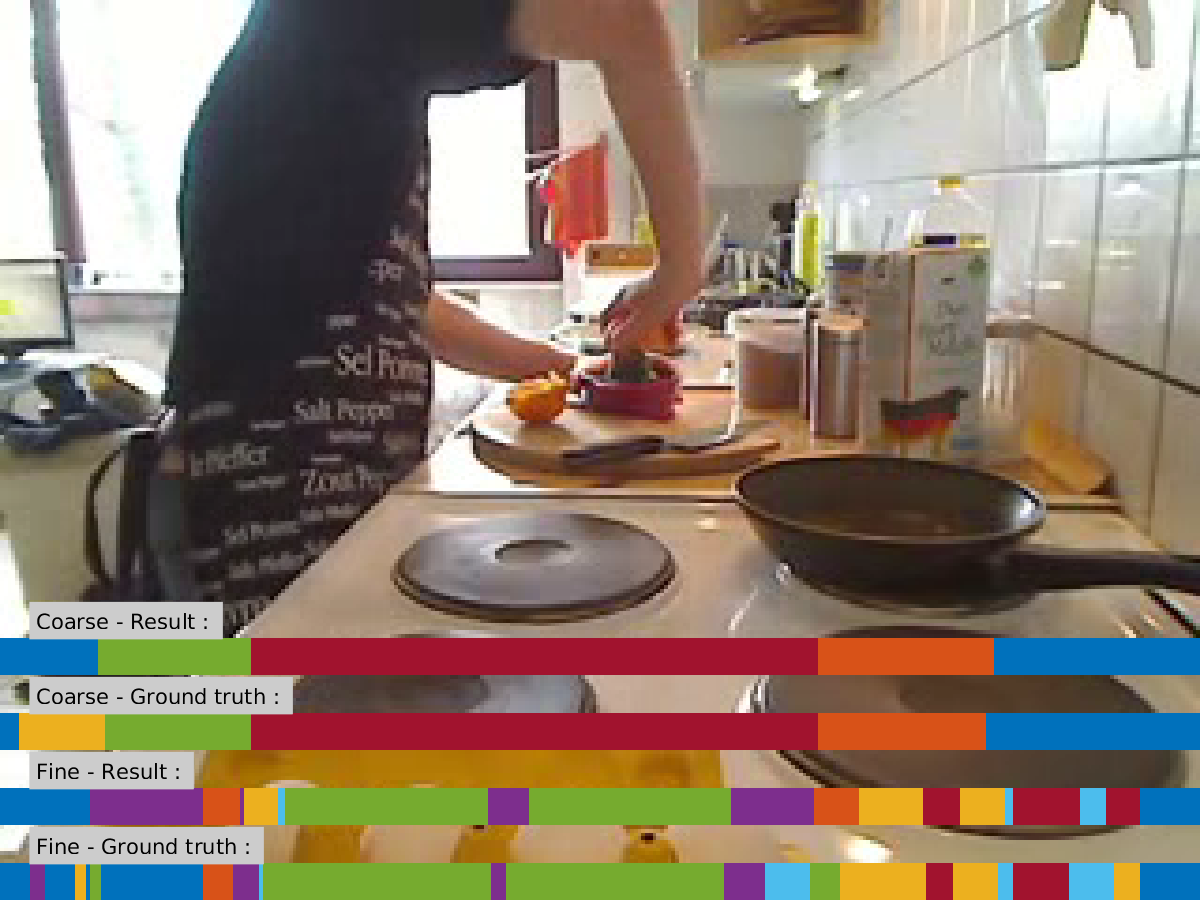
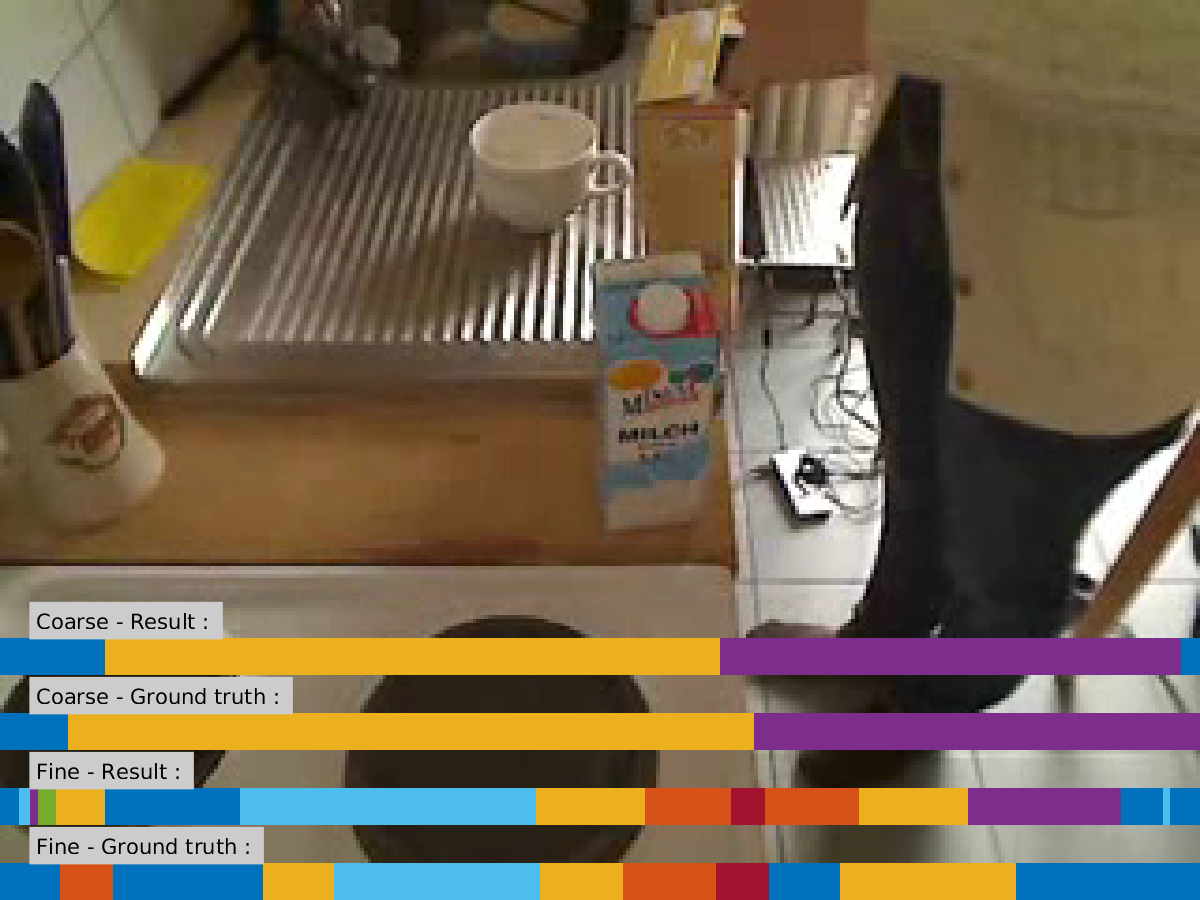
Illustration of the actions
Two sample pictures for the activities ‘juice’ and ‘cereals’ with coarse and fine annotations:
Citation
The benchmark and database are described in the following article. We request that authors cite this paper in publications describing work carried out with this system and/or the video database.
H. Kuehne, A. B. Arslan and T. Serre. The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities. CVPR, 2014. PDF Bibtex
H. Kuehne, J. Gall and T. Serre. An end-to-end generative framework for video segmentation and recognition. WACV, 2016. PDF Bibtex Project Website
Data
Videos: BreakfastII_15fps_qvga_sync.tar.gz (3.6 GB)
Videos as multipart files: part 1, part 2, part 3, part 4, part 5, part 6
To extract the files, please use the command line to go to the download directory and use this command:
cat Breakfast_Final.tar* | tar -zxvf –
Pre-computed dense trajectoires:
One large file: dense_traj_all.rar (~220GB)
Splitted in four: dense_traj_all_s1.tar.gz (~37GB) dense_traj_all_s2.tar.gz (~57GB) dense_traj_all_s3.tar.gz (~42GB) dense_traj_all_s4.tar.gz (~75GB)
Frame-based precomputed reduced FV (64 dim): breakfast_data.tar.gz (~1GB)
I3D feature (pretrained on Kinetics, no fine-tuning) for rgb and flow (2048 dim): bf_kinetics_feat.tar.gz (27.7 GB)
Coarse segmentation information: segmentation_coarse.tar.gz
Fine segmentation information: segmentation_fine.tar.gz
The splits for testing and training are:
s1: P03 – P15
s2: P16 – P28
s3: P29 – P41
s4: P42 – P54
For further information, please contact: kuehne [@] ibm . com

Breakfast dataset by H. Kuehne, A. B. Arslan and T. Serre is licensed under a Creative Commons Attribution 4.0 International License.
Based on a work at http://serre-lab.clps.brown.edu/resource/breakfast-actions-dataset/.
Code
Current version of the system is available on GitHub: https://github.com/hildekuehne/HTK_actionRecognition
The previous matlab demo for action recognition on htk is still available here: demo_bundle . To run the example, please follow the instructions in the README file
Current Benchmarks
Fully supervised
The dataset has been a applied to various use cases so far. For fully supervised learning the tasks are Activity classification (classify the full videos according to the 10 activity classes) ans Temporal segmentation (detect and classify the 48 action units within the videos).
Activity classification
Temporal Segmentation
Weakly supervised
For weakly supervised learning, we consider that at training time only the videos with the respective transcripts (the action order as they occur in the video) are given without any action boundary information. The tasks are Temporal alignment (the transcripts of the test videos are given at test time and the respective actions need to be detected) ans Temporal segmentation (detect and classify the 48 action units within the videos without transcripts).
Temporal Alignment
Temporal Segmentation
About the page
CONTACT
For questions about the datasets and benchmarks, please contact Hilde Kuehne ( kuehne [@] ibm . com ).
Acknowledgments
This work was supported by ONR grant (N000141110743) and NSF early career award (IIS- 1252951) to TS. Additional support was provided by the Robert J. and Nancy D. Carney Fund for Scientific Innovation and the Center for Computation and Visualization (CCV). HK was funded by the Quaero Programme and OSEO, the French State agency for innovation.
LOG
- 04/10/2014 first version of the web page
- 03/22/2016 second version of the web page
- Databases
- ClickMe
- The multi-cue boundary detection dataset
- HMDB: a large human motion database
- The Breakfast Actions Dataset